Supervised Duplicate Classification - Feature Selection
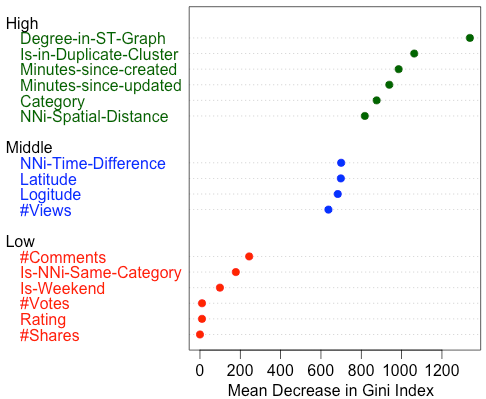
Some of the features we have directly extracted from the reports’ description are:
- Number of views
- Number of comments
- Number of shares (in social networks)
- Rating / Voting
- Address (ZIP Code)
- Coordinates
Furthermore, it is also possible to extract information about the user who is reporting the issue when when this kind of information is available in the dataset. Additionally to the already available attributes of a report, we also have extracted some extra features regarding its spatio-temporal neighborhood:
- Spatial Distance to k-nearest neighbours (NNi-Spatial- Distance)**
- Temporal Distance to k-nearest neighbours (NNi- Temporal-Distance)**
- A Category, derived from the textual report description
- A boolean flagging if the k-nearest neighbour is of the same type / category of the report in question (Is-NNi- Same-Category)**
- A boolean flagging if the report has been marked as du- plicate by our unsupervised clustering (Is-in-Duplicate- Cluster)
- A boolean flagging if the report has been submitted on a weekend (Is-Weekend)
- The degree of the vertex representing the report in the ST-Graph (Degree-in-ST-Graph)
- SecondsActiveUpdate captures the temporal length the users interact with a report: time passed since the generation of the reports and its last update